Ce cours vous expliquera comment faire entrer l'audio en temps réel dans votre machine pour une analyse de son signal. L'intérêt de ce procédé est de pouvoir chanter ou gueuler à sa machine. On pourrait également imaginer des dispositifs pour des VJs, ou imaginer quelque chose d'encore plus novateur. mais pour l'instant nous allons plutôt chanter ou gueuler (au choix), car il illustre bien le fonctionnement de l'entrée audio.
Un des avantages d'utiliser l'entrée audio dans une installation interactive, tient au fait que la machine compresse l'ensemble de votre corps dans un canal extrêmement réstreinte : la valeur de fluctuation due aux vibrations du membrane du microphone. mais contrairement à d'autres interfaces de compression, nous avons énormément d'expérience corprelle de la compression audio, et nous sommes bien habitués à compacter dans notre voix énormément d'affectations hautement qualitatives. Aussi, en bonus, nous accompagnons souvent cette compression d'un mouvement physique, comme si la voix était une extension de notre rapport kinésthésique au monde (d'ailleurs il l'est, en quelque sorte, car les cordes vocales sont des muscles parmis d'autres). En conséquence, pour faire bouger les corps des joueurs de votre installation, le plus simple est parfois de construire un dispositif sonore réactif.
Côté technique, ce cours sera basé sur l'utilisation de la bibliothèque externe ESS. Si vous n'avez pas encore lu l'article sur comment installer les bibliothèques externes, nous recommandons sa lecture avant de débuter ce cours. Concernant ESS, Nous aurions pu utiliser d'autres bibliothèques de traitement et de génération audio, comme Sonia, par exemple, mais celles-ci nécessitent des plug-ins - ce qui est un peu dûr pour le pauvre Internaute qui doit aller cliquer sur un installateur avant de jouer, et nous voulons une solution plus facile à mettre en ligne.
I (love|hate) you
Voici deux œuvres programmées qui utilisent l'entrée audio en temps réel d'une manière très claire :

La première, messa di Voci, est de Golan Levin et Zachary Lieberman. Il montre les jolies choses qu'on peut faire avec sa voix, bref la part créative de l'utilisation de la voix. On chante, et sa voix dessine des formes. Il est en quelque sorte le descedent des expérimentations de John maeda en 1995 et son Reactive Square.
La deuxième est d'Amy Alexander et s'appelle Scream. Il a été conçu pour pouvoir gueuler à sa machine, genre le soir du 2 novembre 2004 aux Etats-Unis en lisant les résultats sur son écran de l'élection présidentielle.
ESS
Processing ne sait pas d'office faire des programmes de ce genre. mais ce n'est pas un problème pour nous, parce que nous avons des dixaines de bibliothèques externes disponibles pour accroître ses possibilités. En plus, ça tombe bien, parce que, comme vous êtes plutôt bon élève, vous avez déjà lu l'article sur l'utilisation des bibliothèques externes dans Processing : vous êtes prêt à aller sur le site de ESS, à cliquer sur " download ", et à l'installer dans votre bibliothèque personelle de Processing. Eh? Quoi? Vous n'avez pas encore lu ce cours ? Oh, ce n'est pas grave, il explique juste qu'il faut copier le dossier Ess dans le dossier libraries de Processing, comme ceci:
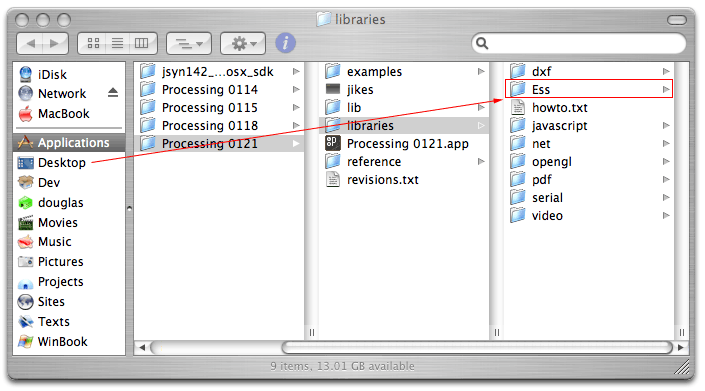
Une fois que nous avons importé cette bibliothèque dans Processing, nous pouvons nous en servir comme si de rien n'était. Les joueurs de notre animation n'auront besoin de rien d'autre que Java qui est déjà installé dans la plupart des cas sur les machines. Ensuite, de notre côté, nous avons de nouvelles fonctionalités dans Processing, qui sont expliqués à travers des exemples et les listes de fonctions sur le site d'ESS :
Niveau
Le moyen le plus simple d'analyser l'entrée audio est de surveiller en permanence son niveau sonore. Cela nous permettra de créer une relation simple entre la voix, par exemple, et une variable. Quand la voix est plus forte, la variable monte, quand elle est plus faible, la variable descend. Ensuite nous utiliserons cette variable pour affecter ce que nous voulons.
Voici le code de départ pour mesurer l'entrée audio. Il est le plus simple possible pour isoler la variable qui nous intéresse :
// il faut dire à Processing qu'il doit ajouter les fonctions d'analyse audio
import krister.Ess.*;
// ces variables seront notre moyen accès à Ess
AudioInput entree_son;
FFT analyse_son;
void setup() {
// taille image
size(400,400);
// couleur
noStroke();
fill(255,0,0);
// démarrer ess
Ess.start(this);
// créer un accès à l'entrer audio
entree_son=new AudioInput();
// démarrer l'analyseur audio (FFT)
analyse_son=new FFT();
// start your engines!
entree_son.start();
}
void draw() {
// fond blanc
background(255);
// chercher le niveau d'entrée (le * 100 est juste pour être un peu plus visible)
float niveau = analyse_son.getLevel(entree_son) * 100;
// dessiner un cercle au milieu de l'écran
ellipse(200,200,niveau*10,niveau*10);
}
/* Fermer correctement l'entrée audio à la fin (tirer la chasse d'eau pour le suivant) */
public void stop() {
Ess.stop();
super.stop();
}Ce qui devrait vous donner quelque chose comme ceci :
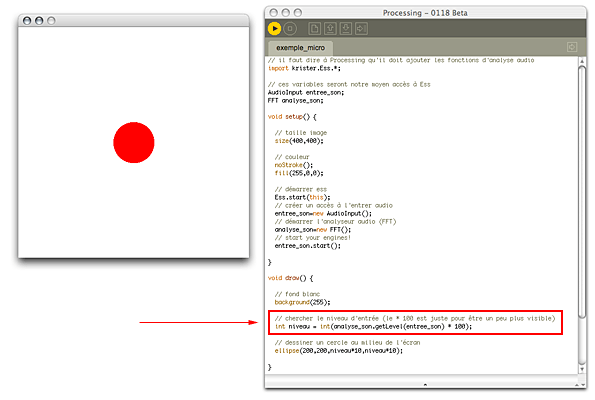
Après tout le bordel d'avoir activé Ess (import), de l'avoir démarré (Ess.start(this)), et puis d'avoir tapé des codes étranges (.getLevel(entree_son)) pour récupérer le niveau, enfin nous avons une variable simple, niveau qui contient un chiffre réel. Il suffit maintenant de juste l'utiliser dans notre programme :
// dessiner un cercle au milieu de l'écran
ellipse(200,200,niveau*10,niveau*10);Ajouter une couche d'abstraction
Si vous avez un petit ballon rouge qui s'agrandit et se rapetit en fonction de votre voix, c'est déjà chouette. Il s'agit là d'un dessin réactif. mais une chose qui nous intéresse dans l'atelier est l'idée de transformer les programmes uniquement réactives en des programmes jouables linl:playability. Un bon départ serait de rajouter une variable globale x...
AudioInput entree_son;
FFT analyse_son;
float x = 200;...et puis d'utiliser niveau pour affecter x qui affectera à son tour l'ellipse, au lieu d'utiliser niveau directement :
float niveau = analyse_son.getLevel(entree_son) * 100;
x += niveau;
x = x % 400;
// dessiner un cercle à la position d'y
ellipse(x, 200 10, 10);De cette façon, nous n'affectons pas les valeurs de l'ellipse directement reactive, mais plutôt avec une variable interposée. Cette approche nous éloigne de la réactivité et nous rapproche de la jouabilité. La machine garde en mémoire la position de l'objet et du coup peut même avoir des aspects de comportement automatiques. Par exemple, la balle pourrait être en train de se déplacer en permanence dans un terrain miné et la voix lui servirait uniquement pour eviter les obstacles.
FFT
Pour une analyse plus " sérieuse " (pfffth@#¿!) du son, nous devons utiliser un système d'analyse qui s'appelle FFT, c'est-à-dire le FFT, ou en français, le " Transformée de Fourier rapide " (c'est dommage d'utiliser autant des termes anglais pour ce qui, en plus, est une invention française. mais dans le langage courrant de l'informatique nous parlons de FFT et non pas de TFR).
Le FFT, en gros, vous donnera non pas une valeur, mais un ensemble de valeurs de l'entrée audio. Vous trouverez un excellent exemple en ligne (inputFFT) sur le site d'Ess, avec les codes sources (InputFFT.pde). Par contre, ce code est un peu compliqué. Voici une simplification de cet exemple, en gardant notre exemple de niveau sonore comme squelette :
// il faut dire à Processing qu'il doit ajouter les fonctions d'analyse audio
import krister.Ess.*;
// ces variables seront notre moyen accès à Ess
AudioInput entree_son;
FFT analyse_fft;
int tampon = 512;
float normalisation;
void setup() {
// taille image
size(400,400);
// couleur
noStroke();
fill(255,0,0);
// démarrer ess
Ess.start(this);
// créer un accès à l'entrer audio
entree_son=new AudioInput(tampon);
// démarrer l'analyseur audio (FFT)
analyse_fft=new FFT(tampon * 2);
analyse_fft.equalizer(true);
// du code pour "normalizer" les valeurs
float min_limit=.005;
float max_limit=.05;
analyse_fft.limits(min_limit,max_limit);
analyse_fft.damp(.1f);
analyse_fft.averages(32);
normalisation = max_limit - min_limit;
// start your engines!
entree_son.start();
}
void draw() {
// fond blanc
background(255);
// chercher le niveau d'entrée (le * 1000 est juste pour être un peu plus visible)
float niveau = analyse_fft.getLevel(entree_son) * 1000;
stroke(255,0,0);
ellipse(200,200,niveau,niveau);
// montrer les valeurs de chaque fréquence
for(int i=0; i<tampon;i++) {
float valeur = analyse_fft.spectrum[i]*width;
line(0, i, valeur, i);
}
}
public void audioInputData(AudioInput theInput) {
analyse_fft.getSpectrum(entree_son);
}
/* Fermer correctement l'entrée audio à la fin (tirer la chasse d'eau pour le suivant) */
public void stop() {
Ess.stop();
super.stop();
}Ce qui devrait vous donner quelque chose comme ceci :
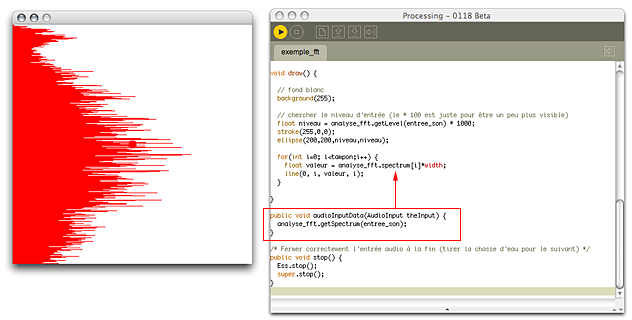
Ce code est évidemment plus longue, et plus compliqué. Au début, nous avons initialisé l'analyseur FFT avec un peu plus de code (mais oui, vous pouvez faire copier-coller, il ne faut pas se gêner). Ensuite, remarquez, comme il est souligné dans l'illustration, que nous avons ajouté un bout de code étrange (public void audioInputData()). Ce code est juste la partie du programme qui dit: va chercher du son pour que je puisse l'analyser.
Ensuite, le reste est plutôt simple : nous augmentons le cercle avec le niveau sonore, puis nous allongons les lignes de chaque fréquence avec l'analyseur FFT.