
Comment se réapproprier les logiciels de génération de texte synthétique et les transformer en puissants outils de changement et d’activisme ?
Alors que nous assistons à l’évolution croissante (et effrénée) de l’intelligence artificielle, cet atelier offert par le Master Media Design a aidé les étudiant.e.x.s à démystifier ces technologies, à comprendre d’avantage le fonctionnement interne de ces bots et à les réutiliser critiquement au sein de pratiques d’art et de design. Par delà les phénomènes de peur et d’engouement amenées par ces nouvelles technologies, les étudiant.e.x.s ont alors collectivement exploré, en premier lieu, de quelles manières ces algorithmes comportent de facto le biais de leurs créateur.e.x.s au niveau du “dataset” utilisé. Dans un deuxième temps, les étudiant.e.x.s du workwhop ont librement exploré comment réapproprier ces technologies à des fins poétiques et politiques. Par un processus d’impression et de découpe de résultats générés à travers de larges feuilles de papiers, chaque étudiant.e.x.s a enfin présenté au groupe de nouvelles narration davantage représentatives des identité.e.x.s de chacun.e.x.s.
- Workshop : Within one body there are millions
- Département : Master Media Design, HEAD – Genève
- Étudiant·e·x : Léonie Courbat, Marine Faroud-Boget, Flore Garcia, Mariia Gulkova, Narges Hamidi Madani, Amaury Hamon, Margot Herbelin, Elie Hofer, Dorian Jovanovic, Tomislav Levak, Louka Najjar, Camilo Palacio, Faust Périllaud, Michelle Ponti, Hanieh Rashid, Tibor Udvari, Nathan Zweifel, Huiwen Zang
- Enseignant·e·x : Sabrina Calvo, Douglas Edric Stanley
- Lien du projet : within-one-body-there-are-millions



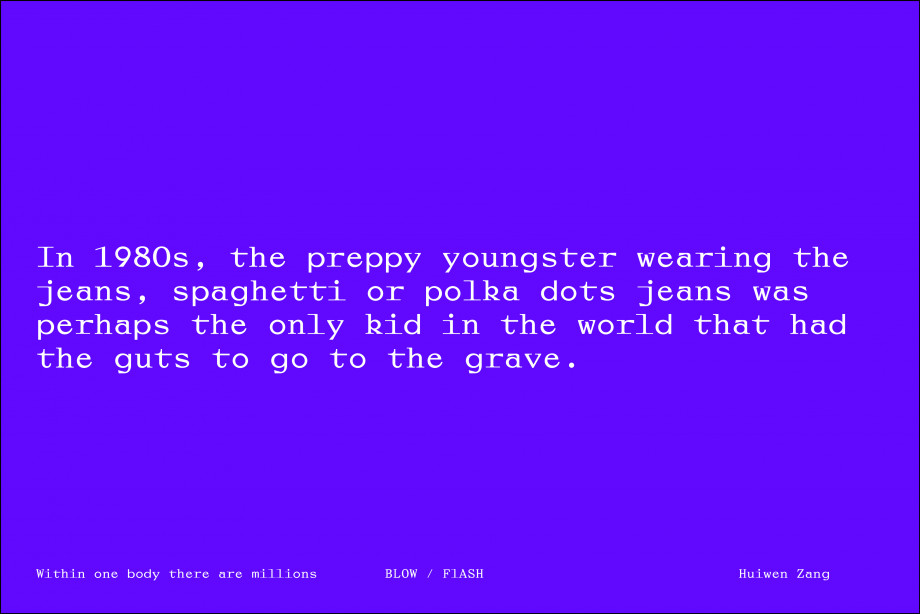







Extrait du brief :
Livrables
- Concevoir un monde textuel
- Construire votre propre jeu de données .txt destiné au ré-entraînement d’un Transformeur Génératif
- Affiner les interactions avec ce générateur de texte
- Il s’agit d’un outil que vous développez pour votre propre workflow personnel
- Ne vous préoccupez pas des interactions orientées utilisateur
- Vous utiliserez cet outil durant le laboratoire Virtual Worlds avec Joana Huguenin
Qu’allons-nous apprendre ?
- Collecter et organiser un jeu de données .txt pouvant être utilisé pour le ré-entraînement d’un transformeur de texte
- Développer une lecture critique et intersectionnelle des questions de biais, de datasets, de communs, et de leur impact sur l’IA
- Affiner un texte jusqu’à en faire une expression poétique d’un monde
- Nettoyer (ou au contraire, « salir ») un dataset d’éléments extrinsèques à l’aide d’outils classiques de traitement du langage naturel (rechercher/remplacer, regex, NLTK, …)
- Mettre en place un notebook Google Colab
- Installer et utiliser des modèles issus de huggingface.co
- Comparer différents transformeurs privés et open source : GPT-2, GPT-3, Bloom, OPT, Codegen, …
Présentation
Voici un lien vers la présentation d’ouverture : head-mmd1-onebodymillions-colab-keynote.pdf
- References
- I Ching, The Book of Changes
- Nothing Forever
- Electric Dreams
- Videodrome
- Consentacle: A Card Game of Human-Alien Intimacy
- Consentacle
- Fractal Time Wave
- Automatic Writing
- Tlön, Uqbar, Orbis Tertius
- Ressources/Tutorials
- GPT-2 Neural Network Poetry
- Colab + GPT-2 Retraining Checklist
- abstract machine-head-tutorial-gpt-2
- Tools/Datasets
- Regular Expression Text Parsing Examples
- Kaggle
- Gutenberg
- Shakespeare.txt (tiny-shakespeare-dialogues.txt, cleaned)
- Shakespeare.txt (full shakespeare, untreated)
- Archive.org
- Dreambank (A collection of over 20’000 dream reports)
- Huggingface
Voici un exemple de la manière dont l’un de ces textes ré-entraînés a été utilisé conformément aux consignes, c’est-à-dire comme un dataset servant ensuite de prompt ou de contrainte auto-conçue pour l’atelier suivant consacré à la modélisation 3D. Cette pièce a été exposée lors de notre exposition Hybrid Strategies à San Francisco.
Extrait du texte d’exposition :
- Titre : magnalumina
- Designer : Elie Hofer
- Date: 2023
- Médium: Large Language Models, txt, 3d modelling
- IA: GPT-NeoX, Huggingface Transformers
- Workshop: Queering AI
- Intervenant·e·s : Sabrina Calvo & Douglas Edric Stanley
- Département : Media Design
Alors que le monde semblait perdre pied face à l’arrivée de chatbots mimétiques reposant sur des IA de plus en plus puissantes, le Master Media Design a organisé cet atelier intensif d’une semaine afin d’inviter les participant·e·s à prendre du recul, à explorer le fonctionnement de ces générateurs de texte synthétique, la manière dont ils sont initialement entraînés, et comment ils peuvent être réinvestis à partir de nouveaux jeux de données sur mesure. En dépassant à la fois la peur et l’hyperbole entourant ces technologies émergentes, les participant·e·s ont été invité·e·s à réfléchir collectivement à la manière dont ces algorithmes véhiculent les biais de leurs concepteurs — des biais inscrits au niveau même des datasets sur lesquels ces technologies ont été entraînées. En « queerisant » les entraînements de base, des mots toxiques et leurs biais historiques surcodés ont pu être relâchés avec soin dans de nouveaux territoires sémantiques plus fluides, où la souffrance binaire s’ouvre sur des paysages poétiques multichromatiques.
Ces ré-entraînements ont ensuite été utilisés comme des modèles textuels sur mesure et à petite échelle, que chaque étudiant·e pouvait mobiliser pour guider la construction d’un monde virtuel à l’aide d’outils classiques de modélisation 3D. Pour son projet Inner Composition, Elie Hofer a ainsi entraîné son propre chatbot interconfessionnel à partir d’un vaste corpus de descriptions historiques de structures architecturales issues de multiples religions. Lors de la conception de son monde virtuel en 3D, Elie consultait son textbot personnalisé afin de déterminer les éléments à modéliser ensuite, instaurant un processus collaboratif dans lequel le chatbot participait activement à la construction du monde.

